




This article shows you an example of how to run a SQL query on BigQuery from Airflow using BigQueryExecuteOperator. There are tons of articles explain what Airflow is, so I won't do that here.
Okie, let's get started! 👨🏻💻
First of all, you'll need at least a table on BigQuery. Here I've already created my table called me_and_coffee.
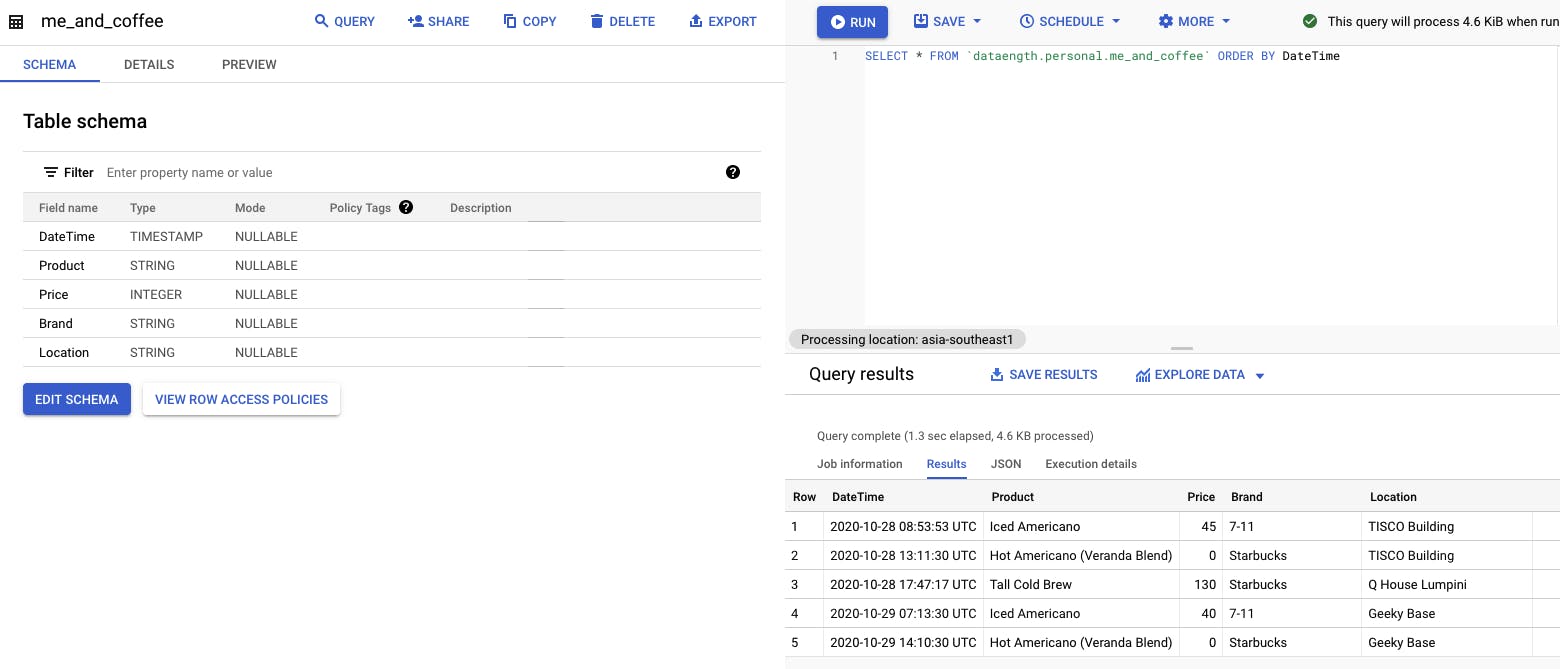
The dataset I'm using in this article is here in case you wanna try it. 😃
Create a Service Account for Airflow
In order to connect to the BigQuery from Airflow, we'll need a credential to access to BigQuery. Therefore, let's create a service account, which is under the IAM & Admin menu.
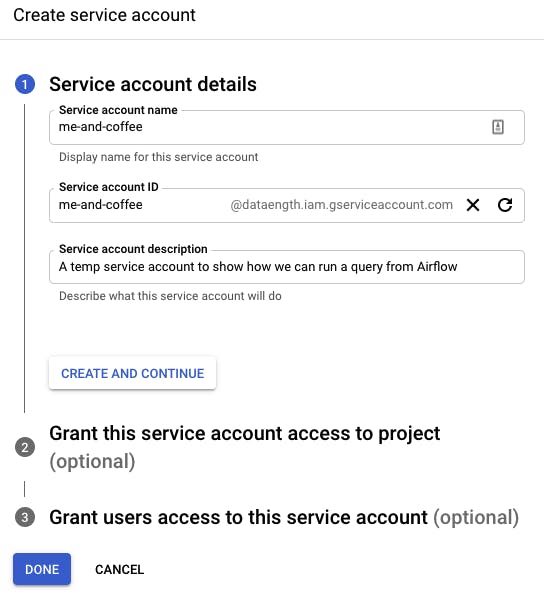
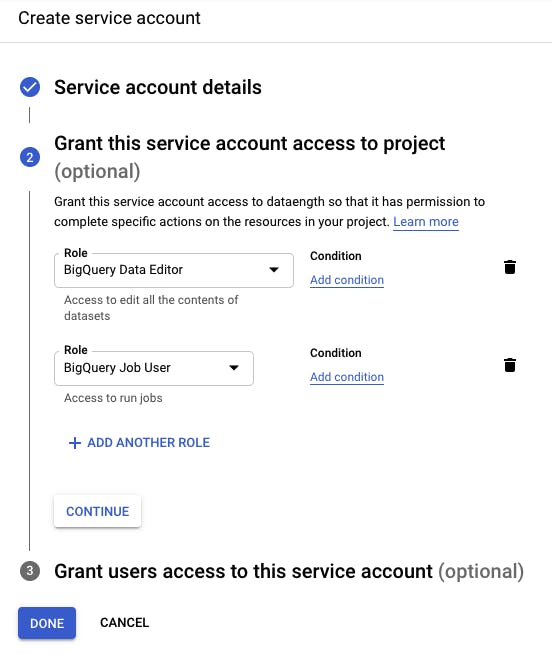
I select the BigQuery Data Editor and BigQuery Job User roles since they'll allow me to create a new table and creating a new table requires a BigQuery job creation. For the third step, I just skip it.
After that, click on your service account, go to the tab "KEYS", and add a new key. It'll pops up a modal as shown in the screenshot below.

Choose JSON and then create. Your JSON file will look similar to this:
{
"type": "service_account",
"project_id": "dataength",
"private_key_id": "secret_private_key_id",
"private_key": "-----BEGIN PRIVATE KEY-----\nmy_private_key\n-----END PRIVATE KEY-----\n",
"client_email": "me-and-coffee@dataength.iam.gserviceaccount.com",
"client_id": "my_client_id",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/me-and-coffee%40dataength.iam.gserviceaccount.com"
}
Set up Airflow Connection to BigQuery
Start your Airflow and then add a new connection.
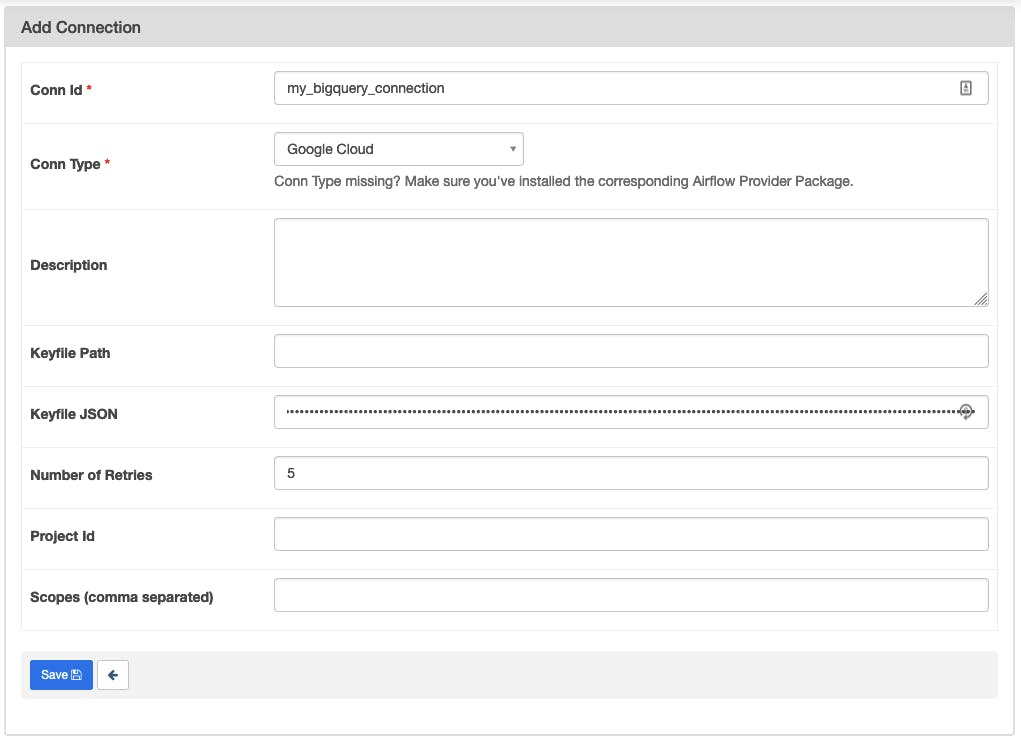
Paste the content of the JSON file you got from the previous section into the "Keyfile JSON" field then save it.
The connection ID my_bigquery_connection will be used later in the next section.
Create a BigQueryExecuteOperator Task to Run Query
Finally, we've come to the point we can use the BigQueryExecuteQueryOperator. 🎉 Yes, it may take some time for the first time we want to use an external system to set up. However, once you did it, it'll be easier afterwards. 🙂
Suppose I wanna find top 5 coffee brands with this query:
SELECT
Brand,
COUNT(Brand) AS BrandCount
FROM
`dataength.personal.me_and_coffee`
GROUP BY
Brand
ORDER BY
BrandCount DESC
LIMIT
5
Here is how we run a query from Airflow:
from airflow.providers.google.cloud.operators.bigquery import BigQueryExecuteQueryOperator
find_top_five_coffee_brands = BigQueryExecuteQueryOperator(
task_id="find_top_five_coffee_brands",
sql="""
SELECT
Brand,
COUNT(Brand) AS BrandCount
FROM
`dataength.personal.me_and_coffee`
GROUP BY
Brand
ORDER BY
BrandCount DESC
LIMIT 5
""",
destination_dataset_table=f"dataength.personal.top_five_coffee_brands",
write_disposition="WRITE_TRUNCATE",
gcp_conn_id="my_bigquery_connection",
use_legacy_sql=False,
)
This operator will result in a new table because I set destination_dataset_table to the table named top_five_coffee_brands. If you don't want a new table, just leave it blank. 😉
I also set write_disposition to WRITE_TRUNCATE, which means the BigQuery will overwrite the table even the table already exists. For more detail, please see the section writeDisposition in the BigQuery Job API doc.
The gcp_conn_id is the connection ID I've got from the previous section.
The use_legacy_sql is whether to use legacy SQL or standard SQL.
Okie, let's see what we've got in the BigQuery after Airflow finishes the task..
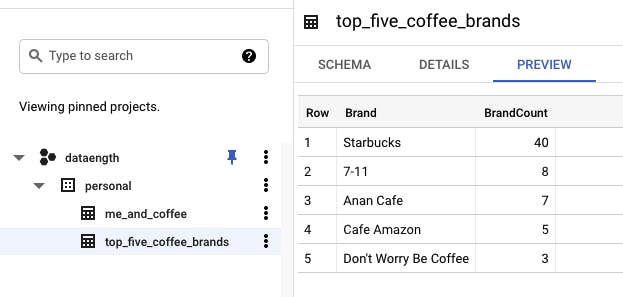
A new table as expected! ✅
In Conclusion
Now we know how to run a BigQuery query from Airflow already. I hope that this would be helpful for those who wanna use Airflow to automate your ETL process, especially when BigQuery is involved.
PS. You can check out my code on GitHub .