มาลองเล่น Dagster เบื้องต้นกัน

I'm a data architect from Thailand. :)
Dagster ตามชื่อของมันเลยคือ data orchestrator สำหรับงานพวก machine learning, analytics และ ETL ซึ่งเป็นเครื่องมือที่ช่วยเรื่อง workflow management อีกตัวหนึ่งที่กำลังมาแรงไม่แพ้ Airflow เลยทีเดียว
จริงๆ แล้ว Nick Schrock (ผู้พัฒนา) ไม่ได้ตั้งใจจะทำออกมาเพื่อที่จะมาเป็น competitor กับ Airflow เลยนะ เค้าพัฒนาขึ้นมาจากประสบการณ์ในการทำงานทางด้าน software engineering และ practices ต่างๆ ที่เค้าเล็งเห็นว่าเครื่องมือตัวนี้เป็น "ของที่มันต้องมี" ในการพัฒนา data applications
เค้านิยามไว้ว่า data application คือ a graph of functional computations that produce and consume data assets
เรื่องข้อดี และความดีงามต่างๆ ของ Dagster จะขอยกเอาไปเขียนไว้ในบทความถัดๆ ไป บทความนี้เราจะมาลองเล่นกันเครื่องมือตัวนี้กันเบื้องต้นก่อนเนอะ 😊
การติดตั้ง
เราไม่จำเป็นต้องสร้างเครื่องหรืออะไรมากมายเลย ขอแค่เรามี Python อยู่บนเครื่องเราพอครับ เริ่มต้นเราสร้าง Python virtual environment ก่อนเลย แล้วติดตั้ง Dagster ตามนี้
python -m venv ENV
source ENV/bin/activate
pip install dagster
การสร้าง Pipeline
ถ้าติดตั้งเสร็จเรียบร้อยแล้ว เราก็มาลองสร้าง pipeline ของเรากันครับ ในตัว pipeline เบื้องต้น จะประกอบไปด้วยสิ่งที่เรียกว่า "solid" มันคือ individual unit of computation หรือเราจะมองมันเป็นฟังก์ชั่นในการคำนวณอะไรสักอย่างก็ได้ และการทำ pipeline ของเราคือการเอา solid แต่ละตัวมาร้อยเรียงกันนั่นเอง
มาสร้างไฟล์ pipeline กันครับ ตั้งชื่อว่า hello_world.py แล้วสร้าง solid แรกของเรากัน
from dagster import solid
@solid
def get_name():
return "Kan"
เสร็จเรียบร้อยครับ solid แรกของเรา 😆 เป็นฟังก์ชั่นน้อยๆ ที่แค่ส่งค่ากลับมาเป็นชื่อผม และผมบอกให้ฟังก์ชั่นของผมเป็น solid โดยการแปะ decorator ไว้บนหัวเฉยๆ เลย
ต่อมาเราจะทำให้มันเป็น pipeline กัน โดยการสร้างอีกฟังก์ชั่นมาเรียก solid ของเราตามนี้ได้เลย
from dagster import pipeline, solid
@solid
def get_name() -> str:
return "Kan"
@pipeline
def hey_pipeline():
get_name()
เรียบร้อย! .. ณ ตอนนี้เรามาลองเพิ่มเข้ามาอีก 1 solid กันครับ ที่รับค่าจาก solid แรก แล้วเอามาเขียนลง log ทำได้ตามนี้
@solid
def hey(context, name: str):
context.log.info(f"Hey, {name}!")
ใน solid เราสามารถรับ context เข้ามาเพิ่มได้ (เป็น optional นะครับ) ซึ่งในตัวแปรนี้ เราจะสามารถเข้าถึงค่าต่างๆ อย่างเช่น configuration ของตัว solid นี้ ตัว logger ค่า resources ต่างๆ รวมไปถึง run ID ด้วย
ซึ่งผมอยากจะให้ solid นี้รับค่ามาจาก solid แรก แล้วเอามาเขียนลง log ซึ่งจำเป็นต้องใช้ logger ที่อยู่ใน context นั่นเองครับ
เสร็จแล้วเราก็จะเอามาประกอบร่างกัน สุดท้ายโค้ดของเราหน้าตาจะเป็นแบบนี้
from dagster import pipeline, solid
@solid
def get_name():
return "Kan"
@solid
def hey(context, name: str):
context.log.info(f"Hey, {name}!")
@pipeline
def hey_pipeline():
hey(get_name())
สังเกตที่ฟังก์ชั่น hey_pipeline ครับ ผมแปะ decorator ที่ชื่อ pipeline เข้าไป และข้างในฟังก์ชั่นนี้ก็เหมือนเราเขียน Python ปกติเลยคือ เรานำเอา output จาก get_name มาเป็น input ให้กับ hey เท่านี้ก็เป็นอันเสร็จสิ้นการเขียน pipeline เบื้องต้นของเราครับ 🥳
แล้วเราจะรัน pipeline นี้ได้อย่างไรนะ? เค้ามีวิธีรัน 3 วิธีครับ
- ผ่าน Dagit (เป็นหน้า UI)
- ผ่าน Dagster Python API
- ผ่าน Dagster CLI
เรามาดูแต่ละวิธีกัน
รัน Pipeline ผ่าน Dagit
เราต้องติดตั้ง Dagit เพิ่มก่อนนะครับ ถึงจะใช้งานได้
pip install dagit
พอติดตั้งเสร็จแล้วให้รัน
dagit -f hello_world.py
เราจะสามารถเข้าผ่านเว็บบราวเซอร์ได้ที่ URL 👉🏻 http://localhost:3000 พอเข้าไปแล้วจะเห็นหน้า UI สวยๆ แบบนี้
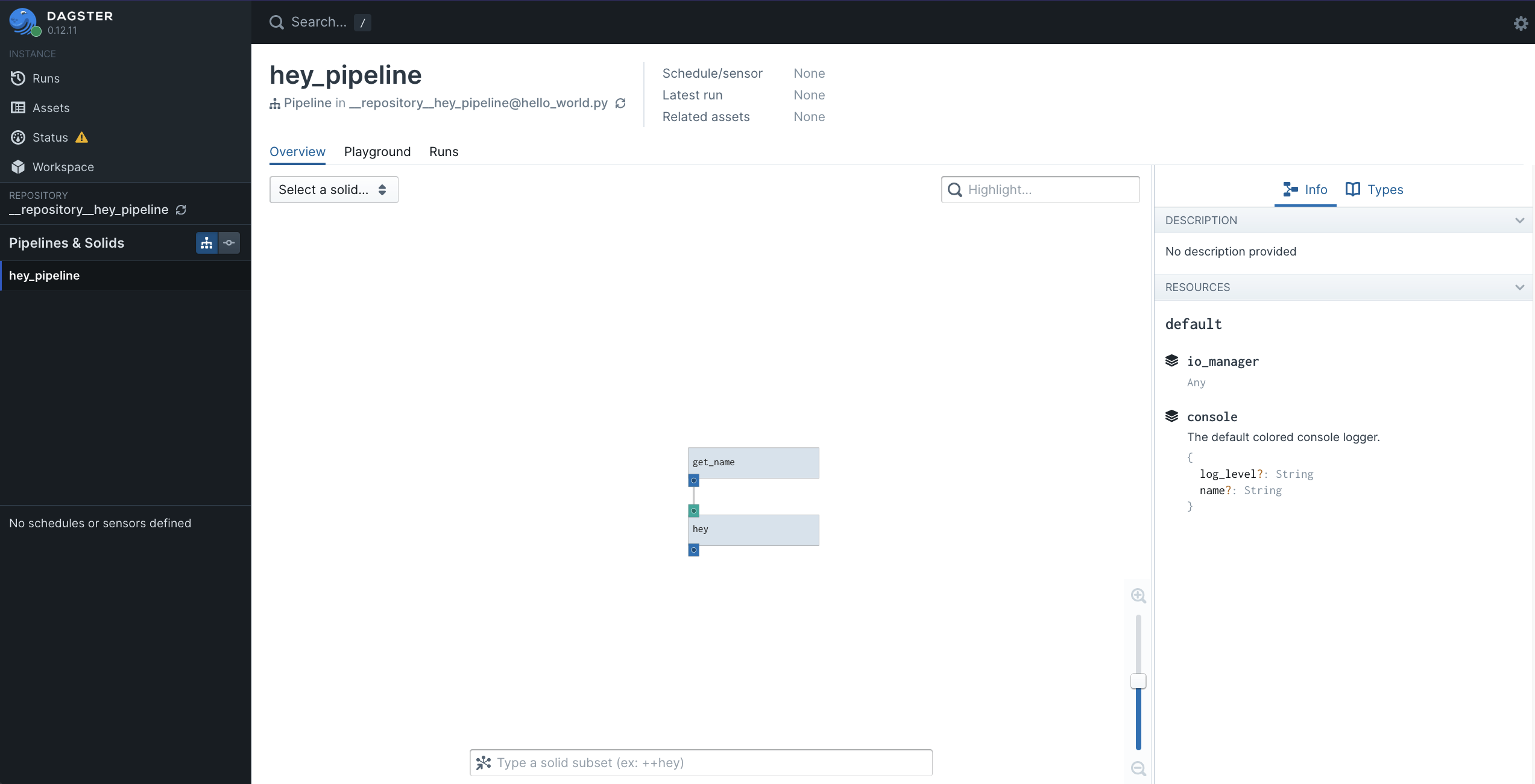
ในหน้านี้ก็จะแสดงหน้าตาของ pipeline ที่เราสร้าง และรายละเอียดของ solid แต่ละตัว ลองกดดูเล่นกันได้
ต่อไปเรามาลองรันกัน จากรูปด้านล่างนี้จะเห็นแท็บ Playground และในหน้า Playground จะมีปุ่ม Launch Execution สีน้ำเงินทางขวาล่างอยู่
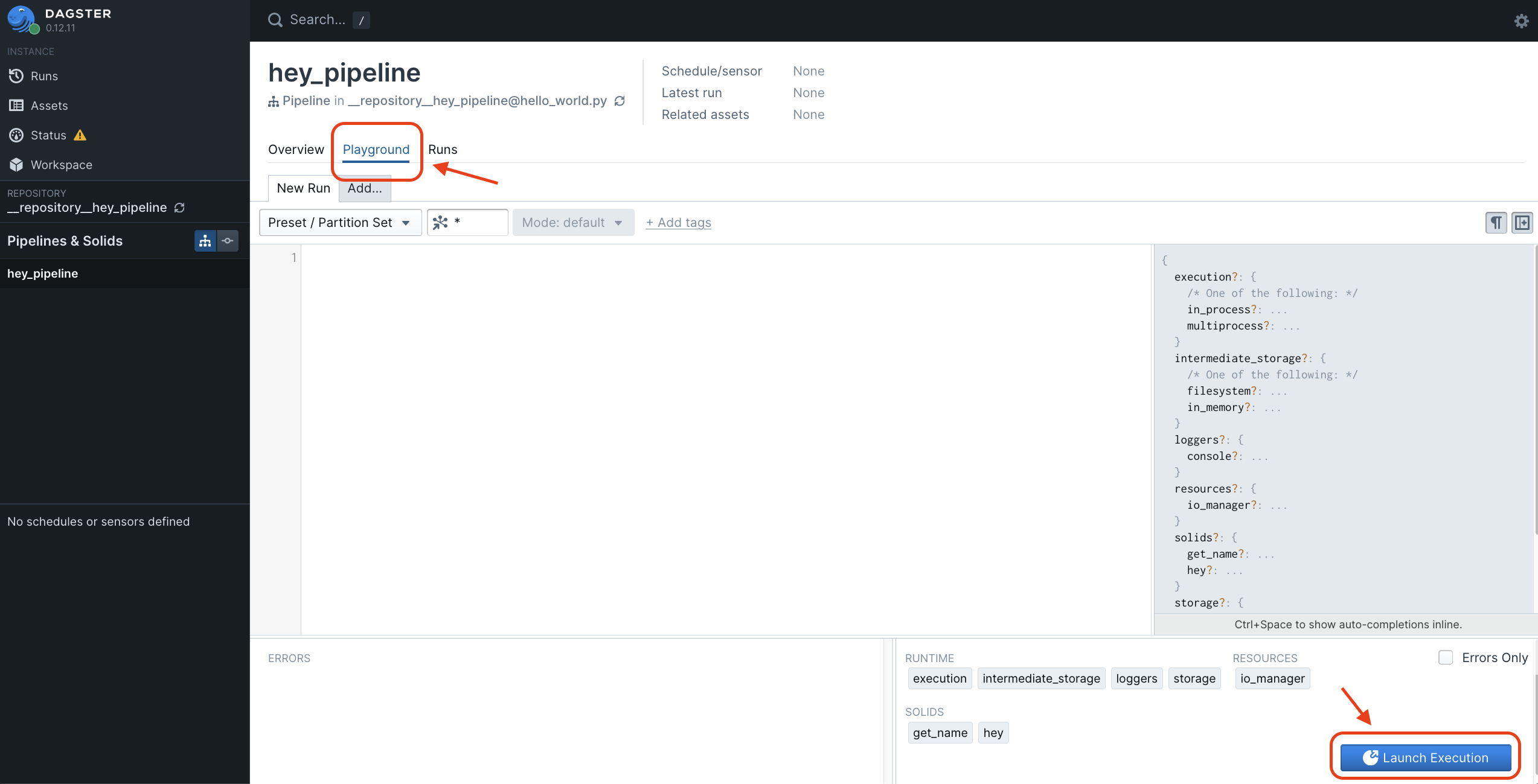
กดเลย! แล้วเราจะเห็นหน้า UI ตามนี้ครับ
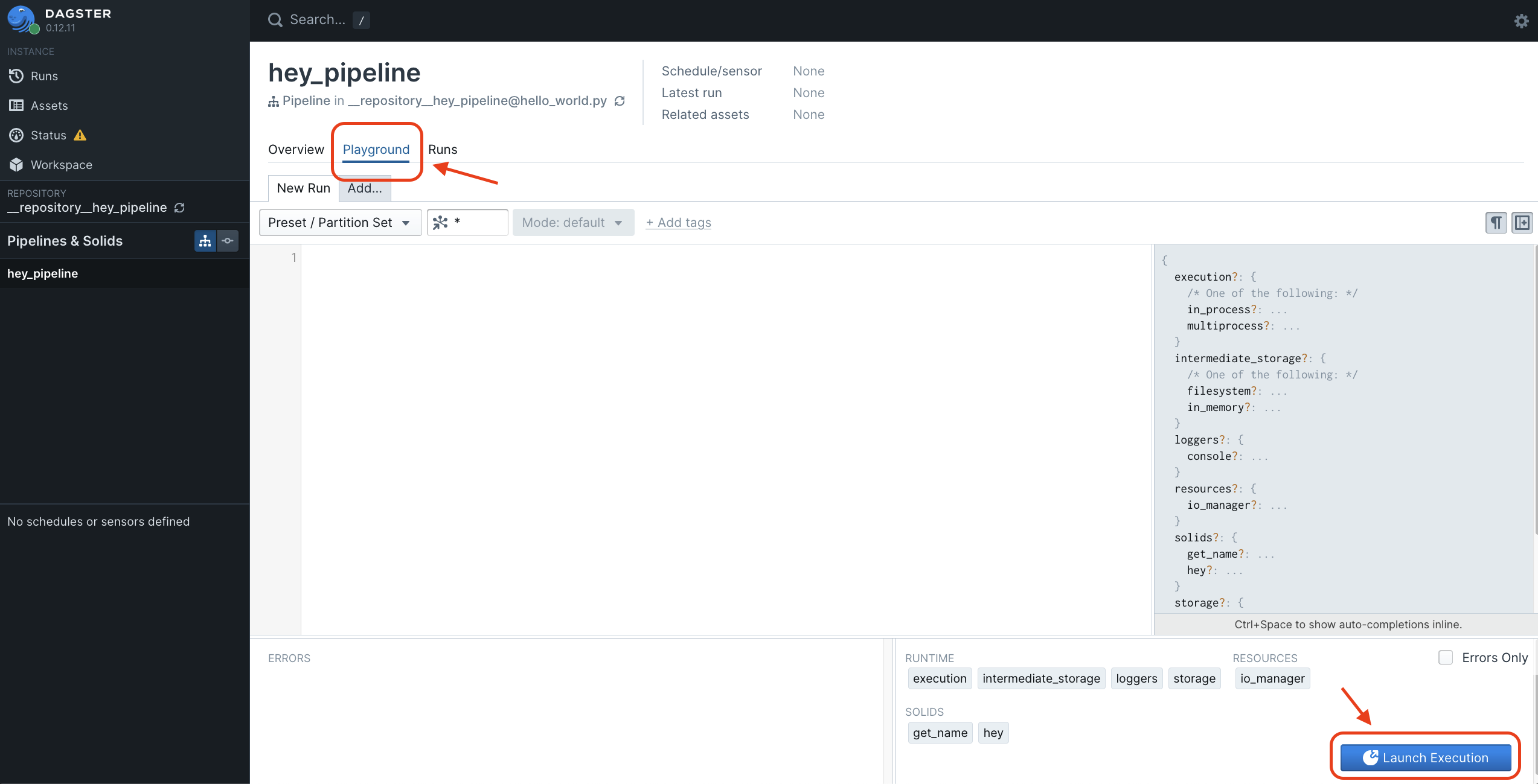
และข้อความที่เราสั่งให้เขียน log ก็ออกมาได้ถูกต้องสวยงามอย่างที่เราต้องการ 😇
ตัว UI ของ Dagster นี้มีความดีงามจริงๆ อยู่คือ มันเป็น Reactive UI นะ ประมาณว่าเวลาที่มีข้อมูลอะไรก็ตามเปลี่ยนแปลง หรือมี event เกิดขึ้น UI นี้ก็จะอัพเดทแบบ real-time เลย ซึ่งหมายความว่าเราอาจจะนั่งดูที่หน้าจอนี้เพลินๆ ได้เลยว่า pipeline เราทำงานถึงไหนแล้ว
ส่วน UI นี้ยังมีอะไรให้ลองเล่นอีกเยอะมากครับ ลองกดๆ กันดูเนอะ 😉
รัน Pipeline ผ่าน Dagster Python API
ก่อนที่เราจะรันแบบนี้ได้ เราจะต้องเพิ่มโค้ดเข้าไปก่อนครับ เราจะต้องใช้ฟังก์ชั่น execute_pipeline ตามนี้
from dagster import (
execute_pipeline,
pipeline,
solid,
)
@solid
def get_name():
return "Kan"
@solid
def hey(context, name: str):
context.log.info(f"Hey, {name}!")
@pipeline
def hey_pipeline():
hey(get_name())
if __name__ == "__main__":
execute_pipeline(hey_pipeline)
พอเรียบร้อยแล้ว เราก็สามารถสั่งคำสั่ง Python ปกติแบบนี้ได้เลย
python hello_world.py
ผลที่ได้จะออกมาทาง stdout แบบนี้ครับ
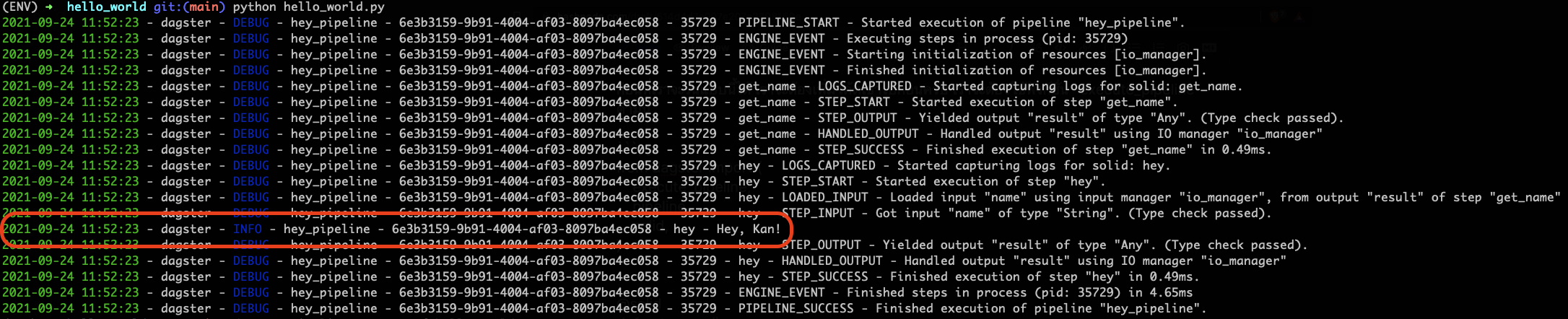
เราก็จะเห็น log ที่เราต้องการออกมาด้วย
รัน Pipeline ผ่าน Dagster CLI
ตรงนี้ผลลัพธ์จะได้เหมือนกับแบบที่เรารันผ่าน Dagster Python API ครับ แค่เปลี่ยนคำสั่งเป็น
dagster pipeline execute -f hello_world.py
สรุปทิ้งท้าย
Dagster ก็เป็นเครื่องมือที่น่าสนใจอีกตัวหนึ่งครับ น่าจะถูกใจกับสาย developer มาก มี developer experience ที่ค่อนข้างดีเลยทีเดียว ได้เขียนโค้ดเป็นฟังก์ชั่นๆ และสามารถรันโค้ด และทดสอบบนเครื่องได้เลย (ถ้าเทียบกับ Airflow เราจะต้องรัน Airflow stack ขึ้นมาก่อน) ใครลองแล้ว ใช้จริงแล้ว คอมเม้นต์มาเล่าให้อ่านกันบ้างนะ 😚
สำหรับ Dagster นี้ผมยังไม่ได้เอาไปใช้ในงานจริงบน production เท่าไหร่ แค่ลองแตะๆ เล่นนู่นเล่นนี่ กำลังคิดว่าจะเอามาลองใช้กับงานพวก data product แล้วเดี๋ยวจะมาเขียนแชร์ให้อ่านกันนะ
ปล. บทความนี้ไม่ได้กล่าวถึงการตั้ง schedule ของ pipeline แต่เราสามารถตั้งได้นะ ถ้าสนใจลองดูเพิ่มเติมได้ที่ Schedules นะครับ
ผมลองอัดคลิปวีดีโอสั้นๆ ไว้ด้วย 📹


