เริ่มต้นกับ dbt
I'm a data architect from Thailand. :)
จากบทความที่แล้วที่เกริ่นว่า dbt คืออะไร ไป เรามาลองใช้กันดูบ้างดีกว่า 👩🏻💻👨🏻💻
สร้างโปรเจค
เรื่องการติดตั้ง dbt ขอให้ตามไปดูที่ Installation กันก่อนนะ มีทั้งการใช้ Homebrew, การใช้ pip และก็การติดตั้งจาก Source Code ซึ่งหลังจากติดตั้งเสร็จเรียบร้อยแล้ว เราจะสร้างโปรเจค dbt ของเราขึ้นมา ขอตั้งชื่อว่า simple_dbt เนอะ
dbt init simple_dbt
เสร็จแล้ว dbt จะสร้าง Project Structure มาให้เราเริ่มต้นแบบนี้เลย
simple_dbt
├── README.md
├── analysis
├── data
├── dbt_project.yml
├── macros
├── models
│ └── example
│ ├── my_first_dbt_model.sql
│ ├── my_second_dbt_model.sql
│ └── schema.yml
├── snapshots
└── tests
7 directories, 5 files
อาจจะดูเยอะ ใจเย็นๆ อย่าเพิ่งตกใจนะครับ จริงๆ แล้วเราก็ไม่จำเป็นต้องตั้งชื่อตามนี้นะ เราสามารถปรับเปลี่ยนได้ที่ไฟล์ dbt_project.yml เอาล่ะ มาลองดูแต่ละอย่างกัน
analysisเอาไว้เก็บพวกสคริป SQL ต่างๆ ที่เราเอาไว้วิเคราะห์ หรือออกรายงาน ตรงนี้จะไม่เหมือนกับโมเดล เพราะว่าเราไม่ได้จะสร้างอะไรใน Database หรือ Data Warehousedataเอาไว้เก็บข้อมูลที่เราจะโหลดเข้าไปในโมเดลของเราdbt_project.ymlเป็นไฟล์ Configuration ของโปรเจคนี้macrosเราจะเก็บพวก Reusable Macros ไว้modelsเป็นโฟลเดอร์ที่เราจะเก็บไฟล์โมเดลของเรา (ในบทความนี้เราจะไม่สนใจของที่อยู่ในโฟลเดอร์exampleนะ)snapshotsเราจะเอาไว้เก็บ Snapshot ของโมเดลของเราtestsเป็นโฟลเดอร์ที่เราจะเก็บชุดทดสอบของเรา
Okie ก่อนที่จะเริ่มใช้งานให้เราไปที่ไฟล์ ~/.dbt/profiles.yml ก่อน เพื่อที่จะสร้าง Profile ในการใช้งานของเรา พอเปิดไฟล์ขึ้นมาแล้วน่าจะเห็นหน้าตาประมาณนี้กัน
default:
outputs:
dev:
type: redshift
threads: [1 or more]
host: [host]
port: [port]
user: [dev_username]
pass: [dev_password]
dbname: [dbname]
schema: [dev_schema]
prod:
type: redshift
method: iam
cluster_id: [cluster_id]
threads: [1 or more]
host: [host]
port: [port]
user: [prod_user]
dbname: [dbname]
schema: [prod_schema]
target: dev
ซึ่งเป็นสิ่งตั้งต้นที่ dbt สร้างให้เรามา เราจะเห็นว่ามีแค่ default และสังเกตว่าเค้ามี dev กับ prod ด้วย ซึ่งแปลว่าเราสามารถแยก Environment ในการันสคริปของเราได้ 😎
มาเพิ่ม Profile ของเรากัน เราจะมาลองต่อแค่กับ Database ที่ชื่อ PostgreSQL กันดู
simple_dbt:
outputs:
dev:
type: postgres
threads: 1
host: localhost
port: 5432
user: postgres
pass: postgres
dbname: dbt_tutorial
schema: dbt_tutorial
target: dev
ในบทความนี้ผมทำ Docker Compose ไว้ ลองเข้าไปดูกันนะ
แล้วถ้าใครอยากปรับเปลี่ยน profiles.yml เพิ่มเติม ตามไปอ่านได้ที่ Configure your profile
โหลดข้อมูลเข้าโดยใช้ Seeds
Seeds เนี่ยจะเป็นไฟล์ CSV ที่อยู่ในโฟลเดอร์ data ในโปรเจคของเรา ซึ่งการใช้งานก็จะเหมาะกับพวกข้อมูลที่นานๆ ครั้งจะเปลี่ยนแปลง โหลดไฟล์ CSV กัน 👉🏻 ที่นี่ก่อนนะ
หน้าตาในโฟลเดอร์ data เราควรจะเป็นแบบนี้
data
├── raw_customers.csv
├── raw_orders.csv
└── raw_payments.csv
เสร็จแล้วให้เราสั่ง
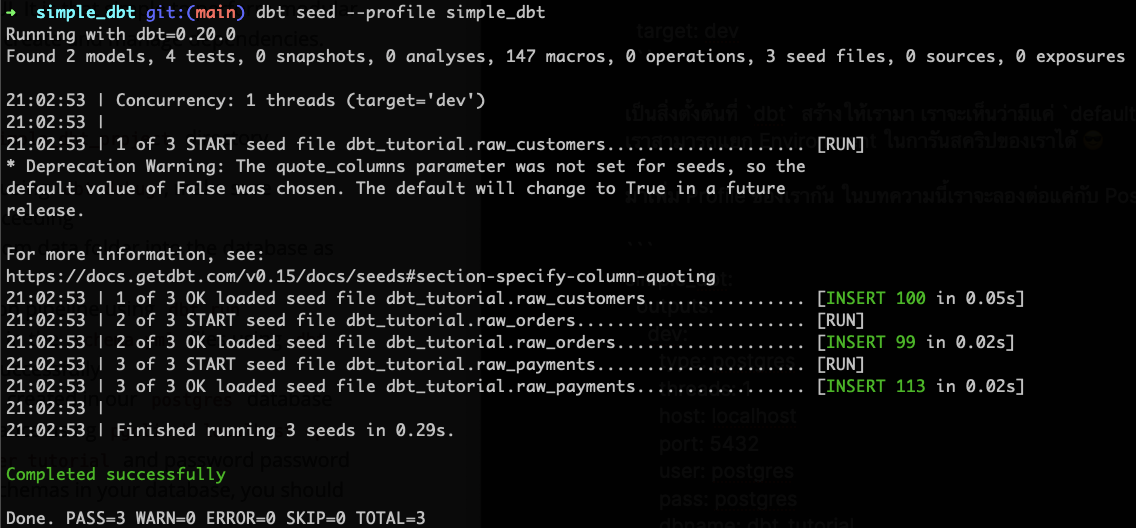
dbt seed --profile simple_dbt
ตรงนี้การใส่ --profile จะเป็นการบอกว่าเราจะใช้ Profile นี้ที่เราต่อกับ PostgreSQL ไว้ในการรัน ซึ่งเราสามารถไปแก้ชื่อได้ในไฟล์ dbt_project.yml จะได้ไม่ต้องใส่ --profile ทุกรอบครับผม
หลังจากรันแล้วจะได้ผลตามนี้
ลองตรวจสอบใน PostgreSQL ของเราดู (คำสั่ง \dn เป็นการให้แสดง Schema ทั้งหมด และ \dt เป็นการให้แสดง Table ทั้งหมดใน Schema นั้นๆ ออกมา)
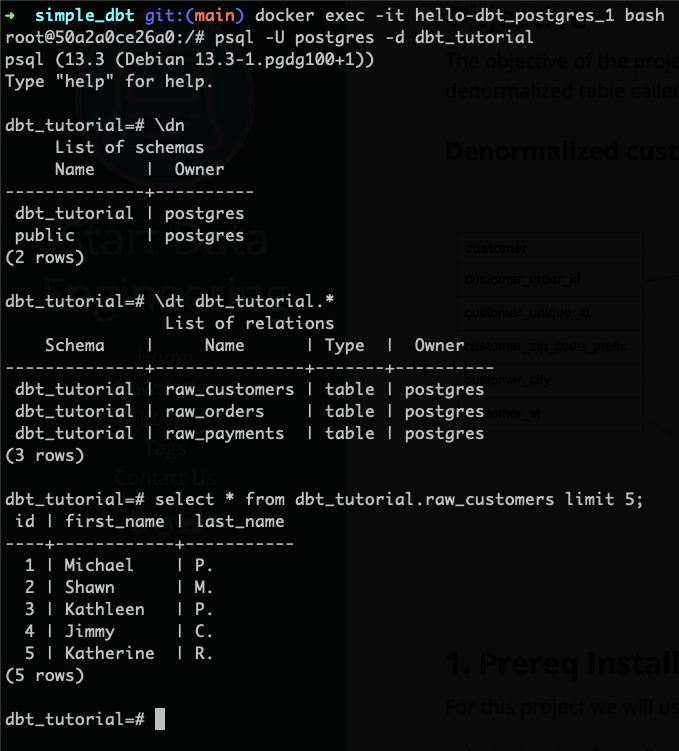
🥳 ข้อมูลถูกโหลดเข้าไปเรียบร้อย แค่สั่ง dbt seed เอง ทำให้เราไม่ต้องไปหาคำสั่งโหลดของ PostgreSQL ซึ่งถ้าเป็นฐานข้อมูลที่แตกต่างกัน คำสั่งการโหลดเข้าไปก็ไม่เหมือนกันล่ะ ตรงนี้ dbt ทำให้เราเลย
ความดีงามอีกอย่างหนึ่งคือ เราสามารถรัน dbt seed ซ้ำได้ครับ มันจะไม่โหลดข้อมูลเข้าไปเพิ่ม 😎
สร้างโมเดล
ต่อไปเราจะลองสร้างโมเดลกัน เริ่มจากสร้างไฟล์ .sql ไว้ในโฟลเดอร์ models ในทีนี้ผมจะตั้งชื่อไฟล์ว่า customer_orders.sql
-- models/customer_orders.sql
select
dbt_tutorial.raw_customers.id as customer_id,
dbt_tutorial.raw_customers.first_name,
dbt_tutorial.raw_customers.last_name,
dbt_tutorial.raw_orders.id as order_id,
dbt_tutorial.raw_orders.order_date,
dbt_tutorial.raw_orders.status
from dbt_tutorial.raw_customers
left join dbt_tutorial.raw_orders
on dbt_tutorial.raw_customers.id = dbt_tutorial.raw_orders.user_id
เป็น SQL ที่ผมจะ Join 2 ตารางเข้าด้วยกัน ซึ่งการสร้างโมเดลแบบนี้ โดย Default แล้ว dbt จะไปสร้าง View ที่ชื่อ customer_orders (ตามชื่อไฟล์) ให้เราครับ ถ้าต้องการให้ dbt สร้างเป็น Table เลย เราจะใส่โค้ดด้านล่างนี้ไว้ที่บรรทัดด้านบนก่อน select
{{ config(materialized="table") }}
ตรงนี้สามารถอ่านเพิ่มเติมได้ที่ Materializations ดูว่าเราสามารถสร้างอะไรได้อีกบ้างจากโมเดล
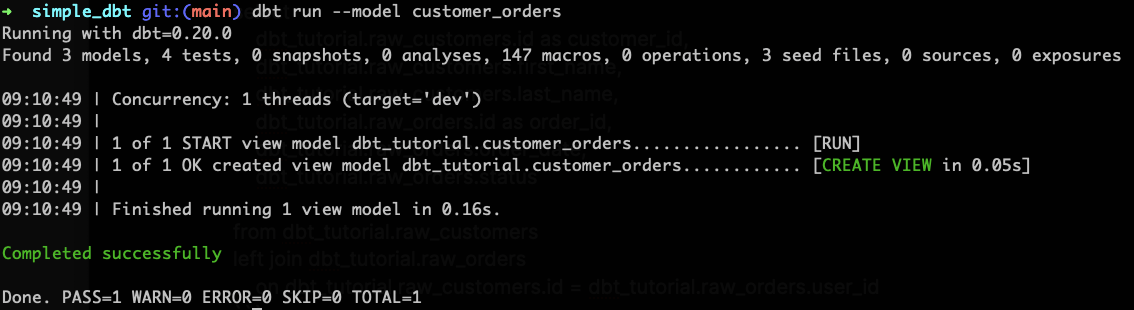
ต่อไปให้เราสั่ง
dbt run --model customer_orders
การใส่ --model เป็นการกำหนดว่าเราจะรันแค่โมเดลนี้เท่านั้นนะ ถ้าไม่ใส่ dbt จะไปหยิบโมเดลทั้งหมดมารัน พอรันปุ๊ปจะเห็น Log ออกมาตามนี้
ลองเข้าไปตรวจสอบข้างใน PostgreSQL กัน (คำสั่ง \dv เป็นการให้แสดง View ออกมาทั้งหมดใน Schema dbt_tutorial)
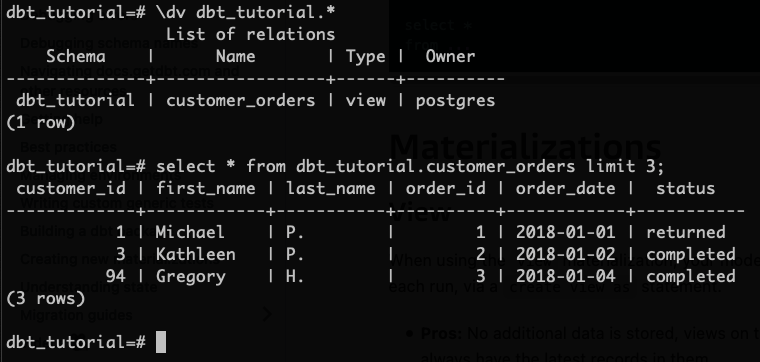
🎉 เราก็ได้ View แรกของเรามาเรียบร้อยจากการใช้งาน dbt ครับ
ถึงตรงนี้หลายคนอาจจะคิดในใจว่า อ้าว.. แบบนี้จริงๆ ก็แค่ไปรัน SQL บน PostgreSQL เลยก็ได้หนิ ผลลัพธ์ก็เหมือนกัน ผมขอตอบว่าใช่ครับ สามารถทำแบบนั้นได้ครับ
ซึ่งตรงนี้ผมมองว่าในมุมของผู้ใช้แบบไม่ได้ Technical มาก การที่เราจะไปเรียนรู้การใช้งาน Database หรือ Data Warehouse นั้นอาจจะมีความยากกว่าการใช้งาน dbt ที่เราแก้ Configuration สั่งรัน แล้วไปรอดูผลที่พวก BI หรือ Dashboard (ที่เชื่อมต่อกับ Database หรือ Data Warehouse ไว้แล้ว)
และถ้ามองในมุมคนในสาย Technical บ้าง เราสามารถที่จะทดสอบ Data Quality สามารถมี Document แบ่งปันความรู้กันในทีม สามารถใช้ Version Control ได้ในการเก็บทั้งโค้ด และ Configuration อีกทั้งเรายังสามารถเขียน SQL แบ่งเป็นส่วนๆ และเอากลับมาใช้ซ้ำได้อีกด้วย
สรุป
บทความนี้จะเป็นการเริ่มต้นใช้ dbt ตั้งแต่ติดตั้ง การตั้งค่าเพื่อเชื่อมต่อกับ PostgreSQL หรือใครจะไปต่อกับ Data Warehouse ของตัวเองเลยก็ได้นะ แล้วก็สุดท้ายเราก็ลองสร้างโมเดลกัน
เดี๋ยวบทความต่อๆ ไปเราจะมาค่อยๆ ดูกันไปนะครับว่า dbt มันสามารถทำอะไรได้อีก 😉



