Scraping ข้อมูลประกาศรับสมัคร Data Engineer บนเว็บ Indeed.com

I'm a data architect from Thailand. :)
เกริ่น
ในสายงาน Data Science & Engineering การทำ Scraping เป็นวิธีหนึ่งในการดึงข้อมูลจากระบบหนึ่งๆ ในกรณีที่เค้าไม่ได้มี API ไว้ให้เราใช้ อย่างเช่น หน้าเว็บไซต์ต่างๆ หรือข้อมูลที่อยู่ในไฟล์พวก PDF เป็นต้น
ถ้าเรามีความสามารถในการเขียนโค้ดทำ Scraping ได้ ก็เหมือนเราติดอาวุธการดึงข้อมูลเพิ่มเข้าไป ที่เราสามารถเลือกหยิบมาใช้ในสถานการณ์ต่างๆ ที่เค้าไม่ได้มีช่องทางให้เราดึงข้อมูลได้
บทความนี้จะพาไปลองเล่นเครื่องมือที่เอาไว้ทำ Web Scraping ตัวหนึ่งครับ มีชื่อว่า Scrapy ซึ่งติดอันดับ Best Open Source Web Scraping Frameworks and Tools in 2020 ที่จัดโดยเว็บไซต์ ScrapeHero เลยทีเดียว 😲
ลงมือทำกัน
เรามาเริ่มลองกันเลยเนอะ เว็บที่ผมจะเอามาเป็น Data Source ของเราคือเว็บ indeed.com ครับ เป็นเว็บที่เอาไว้ประกาศหางานต่างๆ ซึ่งในบทความนี้เราจะมาลองดึงข้อมูลประกาศรับสมัคร Data Engineer ในกรุงเทพฯ กันดู
ก่อนอื่นเราลองค้นหาข้อมูลดูกันก่อน เพื่อให้ได้ URL ที่เราต้องการที่จะเขียนโค้ดเข้าไปดึงหน้าเว็บมา ในทีนี้ผมลองค้นหาคำว่า "data engineer" และเลือกเป็นพื้นที่ใน "กรุงเทพมหานคร" ตามในรูปด้านล่างนี้เลย 👇🏻
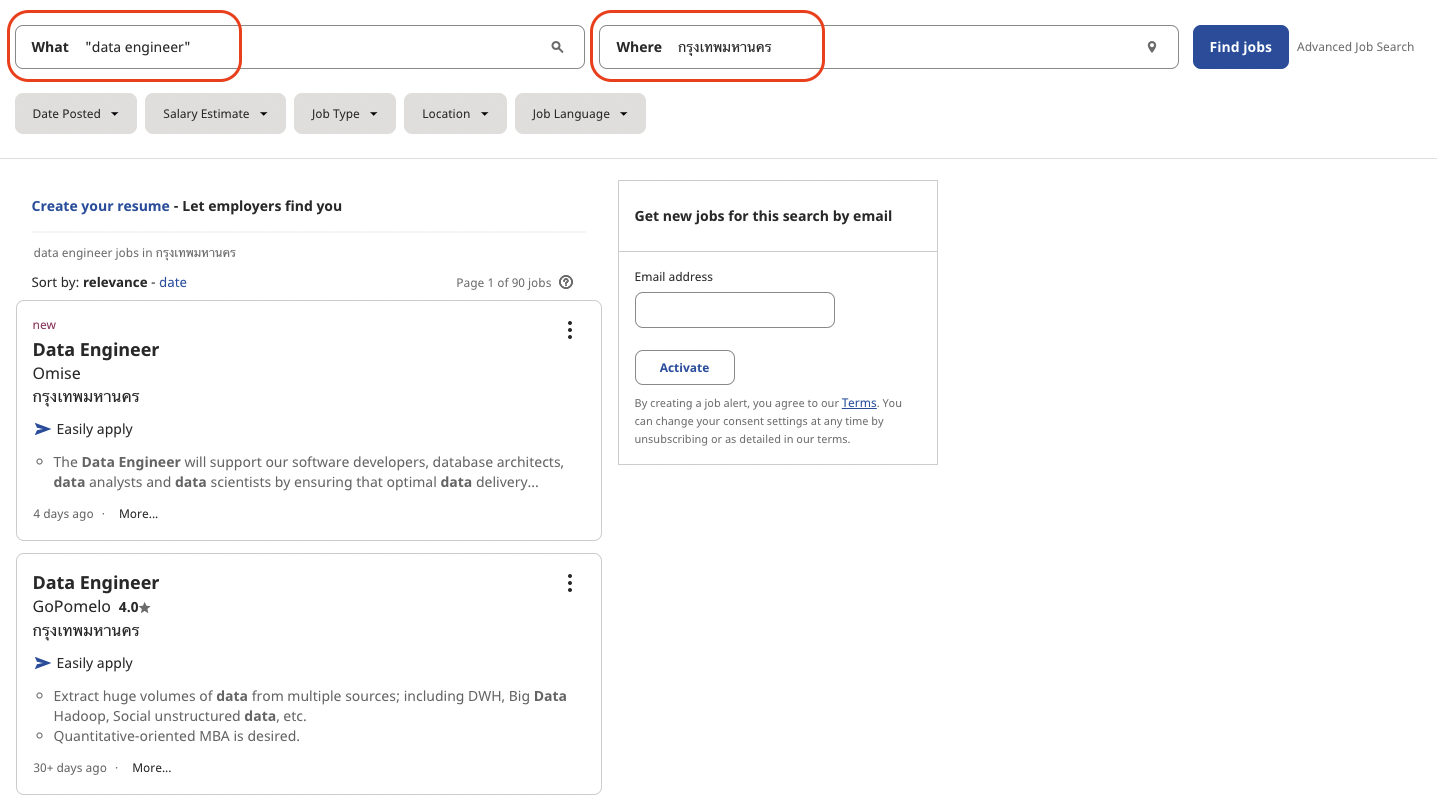
URL หลังจากค้นหาแล้ว ที่ผมได้มาจะมีหน้าตาประมาณนี้ https://th.indeed.com/jobs?q=%22data+engineer%22&l=%E0%B8%81%E0%B8%A3%E0%B8%B8%E0%B8%87%E0%B9%80%E0%B8%97%E0%B8%9E%E0%B8%A1%E0%B8%AB%E0%B8%B2%E0%B8%99%E0%B8%84%E0%B8%A3
จุดประสงค์หลักของผมคือ ผมจะดึงข้อมูลประมาณนี้ของแต่ละโพสต์ที่ประกาศรับสมัคร Data Engineer
- ชื่องาน (Title)
- ชื่อบริษัท (Company Name)
- ที่ตั้งบริษัท (Company Location)
- ลิ้งค์ไปยังงานนั้นๆ (URL)
ทีนี้เราก็ต้องมาดูกันแล้วล่ะว่า เราจะดึงข้อมูลตรงที่ประกาศหารับสมัครได้อย่างไร ตรงจุดนี้เราต้องใช้ความรู้ทางด้าน HTML กันสักหน่อย ตรงนี้ให้เรา Inspect ตรงข้อมูลที่เราต้องการบนหน้าเว็บ แล้วสังเกตตรงโค้ดส่วนที่มีข้อมูลที่เราต้องการครับ
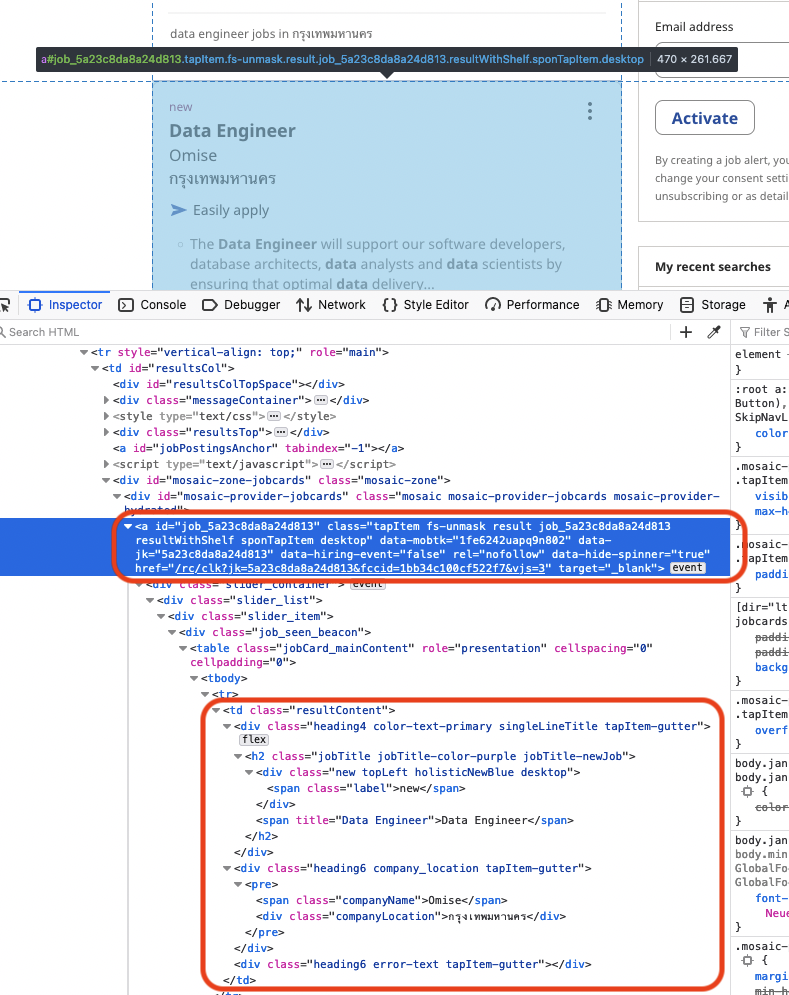
จากรูปด้านบน ข้อมูลที่ผมอยากได้จะอยู่ในกรอบสีแดงครับ ผมจะพยายามดึงข้อมูลเหล่านี้ออกมาล่ะ มาเริ่มเขียนโค้ดกันเลย
ผมจะสร้าง Virtual Environment สำหรับงานนี้มาก่อน
python -m venv ENV
source ENV/bin/activate
แล้วก็ติดตั้ง Scrapy
pip install scrapy
จากนั้นผมสร้างไฟล์ main.py ขึ้นมา แล้วขึ้นโครงไว้ตามนี้
import scrapy
from scrapy.crawler import CrawlerProcess
class MySpider(scrapy.Spider):
name = "indeed_spider"
if __name__ == "__main__":
process = CrawlerProcess()
process.crawl(MySpider)
process.start()
การใช้ CrawlerProcess แบบนี้ จะทำให้เราสามารถเรียกใช้ Scrapy ในสคริปของเราได้ครับ ถ้าดู Tutorial ของเว็บเค้าแล้ว อาจจะเจอแต่แบบที่รัน Scrapy แยกเป็น Standalone
เวลารันก็สั่ง
python main.py
OK หลักจากที่เราได้โครงแล้ว จะมาเริ่ม Scraping กัน โดยสิ่งที่เราต้องทำคือเราต้องพัฒนาเมธอดที่ชื่อ parse ครับ ตาม API ของ Scrapy ซึ่งเดี๋ยวมันจะมาเรียกฟังก์ชั่นนี้ให้เราเอง
SEARCH_URL = "https://th.indeed.com/jobs?q=%22data+engineer%22&l=%E0%B8%81%E0%B8%A3%E0%B8%B8%E0%B8%87%E0%B9%80%E0%B8%97%E0%B8%9E%E0%B8%A1%E0%B8%AB%E0%B8%B2%E0%B8%99%E0%B8%84%E0%B8%A3"
class MySpider(scrapy.Spider):
name = "indeed_spider"
start_urls = [SEARCH_URL,]
def parse(self, response):
job_links = response.css("#mosaic-provider-jobcards a")
for each in job_links:
if "id" not in each.attrib:
continue
url = each.attrib["href"]
jk = url.split("&")[0].split("=")[1]
job_url = f"{SEARCH_URL}&vjk={jk}"
title = each.css(".jobTitle span::attr(\"title\")").get()
company_name = each.css(".companyName::text").get()
company_location = each.css(".companyLocation::text").get()
print(title, company_name, company_location, job_url)
สิ่งที่โค้ดชุดด้านบนนี้ทำคือ ตัว Scrapy จะไปเข้า URL ตามที่เรากำหนดไว้ที่ตัวแปร start_urls ครับ (ใช้ชื่อแบบนี้ตาม Scrapy API) เสร็จแล้วมันจะส่ง Response เข้าไปที่เมธอด จากนั้นแล้วเราจะสามารถใช้ CSS Selector หรือถ้าใครถนัด XPath ก็สามารถใช้ได้เช่นกันครับ 😉
ผลลัพธ์ที่ได้จากโค้ดด้านบนจะเป็นไปตามรูปด้านล่างนี้
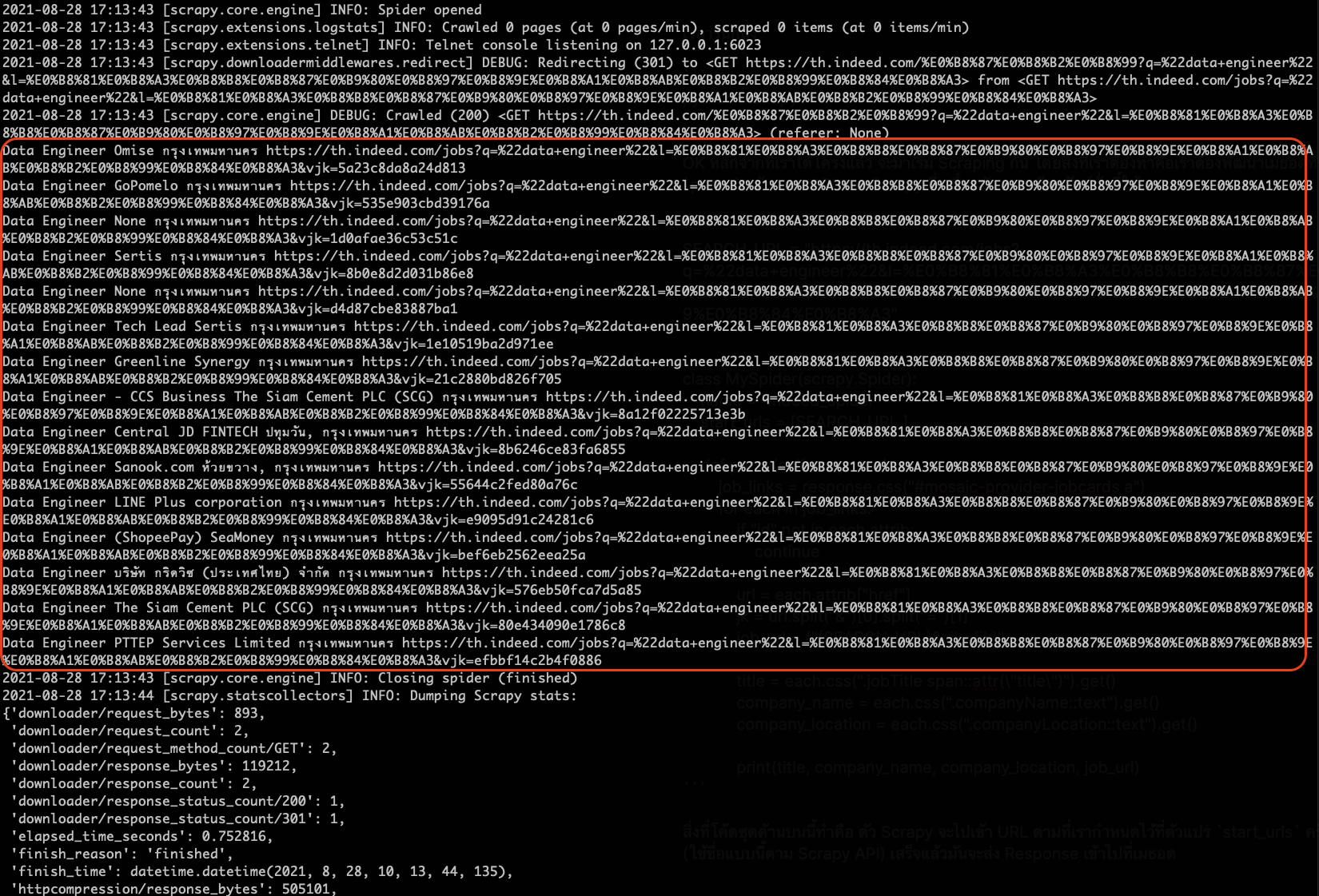
🎉 ผมสามารถดึงข้อมูลจากหน้าเว็บ Indeed ได้แล้ว ซึ่งข้อมูลตรงนี้เราสามารถเอาไปต่อยอดได้ครับ เช่น เอาไปเขียนลงไฟล์ CSV แล้วโหลดขึ้นไปยัง Data Warehouse เพื่อวิเคราะห์ ดูเทรนด์อะไรต่อได้
ถ้าอยากได้ข้อมูลมากกว่านี้ก็สามารถเขียนเพิ่มในเมธอด parse ให้มันอ่านหน้าถนัดๆ ไปก็ได้เช่นกันนะ
ผมเขียนโค้ดทั้งหมดไว้ที่ GitHub 👉🏻 Scraping Data Engineer Jobs on Indeed ก็ลองเข้าไปดูกันได้นะครับ
สรุป
การทำ Scraping สามารถเป็นอาวุธที่ชาว Data ควรที่จะมีติดตัวไว้ จากประสบการณ์ของผมเองที่ผ่านมา ยังไงก็ต้องได้ใช้แน่ๆ ไม่มากก็น้อย 😎 แล้วก็อยากให้คำนึงถึงเรื่องหลักๆ 2 เรื่องคือ
- ถ้าหน้าเว็บเปลี่ยน เราต้องแก้โค้ดตาม การทำ Monitoring ก็จะสามารถช่วยตรงนี้ได้
- การที่เราไปเรียกหน้าเว็บเค้า มันก็เป็นการโหลดเซิฟเวอร์ของเค้าด้วย เวลาใช้ก็พยายามอย่างไปยิงเว็บเค้ารัวๆ กันนะครับ
Scrapy นี่ก็ดูเป็นเครื่องมือที่น่าใช้งาน และดูเขียนโค้ดไม่ได้วุ่นวายมาก ตัว Document ก็เขียนไว้ละเอียดดี แล้วที่ผมเคยใช้ก็มี Beautiful Soup ที่ค่อนข้างที่จะ Low-Level หน่อย ตัว requests-HTML ก็จะดู Friendly ขึ้นมา แล้วก็สามารถทำ Async ได้ด้วย ส่วนใครเคยใช้ตัวไหน ชอบตัวไหน คอมเม้นต์แนะนำกันได้นะครับ 😇


