การจัดการโมเดลใน dbt และการทดสอบ
I'm a data architect from Thailand. :)
ก่อนหน้านี้ผมเขียนไป 2 บทความเกี่ยวกับ dbt ถ้าใครยังไม่ได้อ่าน ขอให้ลองย้อนกลับไปอ่านก่อนนะครับ 😉
เนื้อหาในบทความนี้อยากจะกล่าวถึง 2 ส่วนหลักๆ คือ การจัดการโมเดล (เบื้องต้น) ใน dbt และการทดสอบ
การจัดการโมเดล
ซึ่งจากบทความก่อนหน้าเราได้สร้างโมเดลหน้าตาประมาณนี้ไป
-- models/customer_orders.sql
select
dbt_tutorial.raw_customers.id as customer_id,
dbt_tutorial.raw_customers.first_name,
dbt_tutorial.raw_customers.last_name,
dbt_tutorial.raw_orders.id as order_id,
dbt_tutorial.raw_orders.order_date,
dbt_tutorial.raw_orders.status
from dbt_tutorial.raw_customers
left join dbt_tutorial.raw_orders
on dbt_tutorial.raw_customers.id = dbt_tutorial.raw_orders.user_id
ซึ่งจริงๆ ก็สามารถนำเอาไปใช้ได้ปกติแหละ ไม่ได้มีปัญหาอะไร แต่ในระยะยาวแล้ว ถ้าต่างคนต่างทำ Ad-Hoc Query แบบนี้ไปเรื่อยๆ การดูแลรักษาโค้ดของเราได้ลำบากมากขึ้นเรื่อยๆ เรามักจะเขียน SQL ในลักษณะที่เป็น Modular ประมาณนี้แทน 👇🏻 โดยเอา WITH clause เข้ามาช่วย
-- models/another_customer_orders.sql
with customers as (
select
id as customer_id,
first_name,
last_name
from dbt_tutorial.raw_customers
),
orders as (
select
id as order_id,
user_id as customer_id,
order_date,
status
from dbt_tutorial.raw_orders
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
orders.order_id,
orders.order_date,
orders.status
from customers
left join orders using (customer_id)
)
select * from final
โค้ด SQL จะดูยาวไปไหน.. 😅 แต่ๆๆ ถ้าเรามองดูถึงความแบ่งแยกเป็นส่วนๆ เราจะเห็นได้ว่า โค้ดด้านบนเรา Query จากตาราง dbt_tutorial.raw_customers เสร็จแล้วเราก็ Query จากตาราง dbt_tutorial.raw_orders และสุดท้ายเราเอา 2 ตารางนี้มา Join กันด้วย Key ร่วม customer_id กลายเป็นตารางที่ชื่อ final
การที่เราทำแบบนี้ บวกกับความสามารถของ dbt แล้ว มันทำให้เราสามารถ Reuse Query ที่เคยเขียนไปแล้วได้ครับ เราสามารถแบ่งไฟล์ another_customer_orders.sql ออกมาเป็น 3 ไฟล์ได้ตามนี้
-- models/customers.sql
with customers as (
select
id as customer_id,
first_name,
last_name
from dbt_tutorial.raw_customers
)
select * from customers
-- models/orders.sql
with orders as (
select
id as order_id,
user_id as customer_id,
order_date,
status
from dbt_tutorial.raw_orders
)
select * from orders
และไฟล์สุดท้าย เราจะใช้ ฟังก์ชั่น ref ซึ่งเป็นฟังก์ชั่นที่สำคัญมากแทบจะที่สุดแล้วของ dbt ที่เราจะเอาไว้ Reference ไปยังโมเดลอื่นๆ ตรงนี้ก็หมายความว่าเราสามารถ Reuse ตัวโมเดล customers กับ orders ได้แล้ว! 🤩
-- models/final.sql
with customers as (
select * from {{ ref('customers') }}
),
orders as (
select * from {{ ref('orders') }}
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
orders.order_id,
orders.order_date,
orders.status
from customers
left join orders using (customer_id)
)
select * from final
เวลาเราจะรัน dbt เนื่องจากเรามี 3 โมเดล เราจะสั่งตามนี้
dbt run --model final customers orders
เราก็จะได้ผลลัพธ์ตามนี้
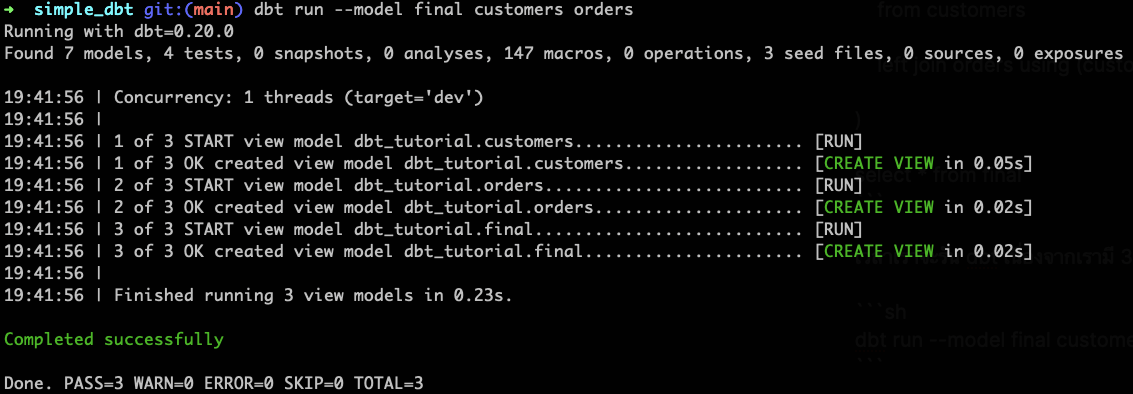
สังเกตว่า dbt เค้าจัดการ Dependency ระหว่างโมเดลให้ด้วยนะ dbt จะไปสร้างโมเดล customers ก่อน ตามด้วย orders และสุดท้ายก็จะมารัน final
ใน PostgreSQL เราก็จะได้มา 3 Views ตามนี้
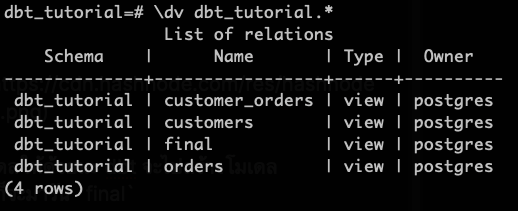
การทดสอบข้อมูล
การทดสอบจะแบ่งออกเป็น 2 อย่าง (อ่านเพิ่มเติมได้ที่ dbt Documentation)
- Data Tests - จะรัน Specific Query กับ Specific Models
- Schema Tests - จะ General กว่า แล้วมี 4 แบบ คือ
unique,not_null,relationshipsและaccepted_values
มาพูดถึง Data Tests กันก่อน ตรงนี้ถ้าใครไม่ค่อยคุ้นกับ SQL อาจจะสับสนเล็กน้อยตอนที่เขียน ผมเองก็ด้วย 😂 คือเราจะเขียน SQL ที่จะได้ผลลัพธ์เป็นข้อมูลที่ "ไม่ควร" มีอยู่ หรือถ้าพูดเป็นภาษาอังกฤษก็ A data test passes if the number of records returned is 0.
ยกตัวอย่างเช่น ถ้าเราต้องการที่จะทดสอบข้อมูลสุดท้ายว่า มันไม่ควรจะมีลูกค้าที่ชื่อ Michael ในข้อมูลของเราเลยนะ เราจะเขียน SQL ประมาณนี้ เอาไว้ที่โฟลเดอร์ tests
-- tests/assert_michael_should_not_be_included.sql
select
*
from dbt_tutorial.final
where first_name = 'Michael';
เวลาเรารัน จะสั่งตามนี้
dbt test --data
ผลลัพธ์ที่ได้ก็ตามคาด
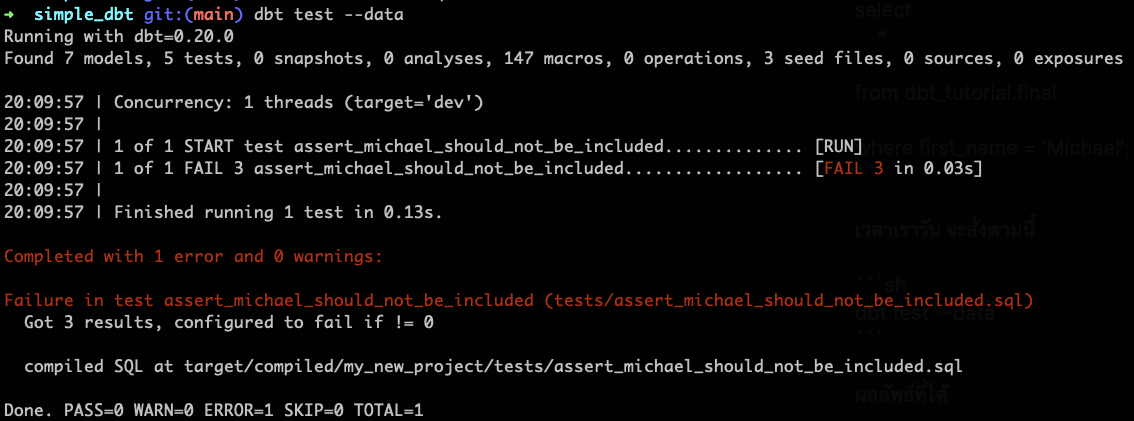
ซึ่งก็ควรจะ Fail จริงครับ เพราะว่าในข้อมูลผมมี Michael อยู่เนอะ 😎 ตรงนี้ก็สามารถเอาไปประยุกต์กันต่อได้ครับ เป็นการตรวจสอบ Data Quality ของเราไปในตัว
มาดู Schema Tests กันบ้าง เป็นอีกการทดสอบหนึ่งที่ช่วยให้เราตรวจสอบ Data Quality ได้เช่นกัน การใช้งานเราจะสร้างไฟล์ .yml ไว้ และควรจะวางไว้ใกล้ๆ โมเดลของเราเลย คือในโฟลเดอร์ models ตามนี้
# models/schema.yml
version: 2
models:
- name: final
columns:
- name: status
tests:
- not_null
- accepted_values:
values: ['placed', 'shipped', 'completed', 'returned', 'return_pending']
จากไฟล์จะหมายความว่าผมกำลังจะทดสอบข้อมูลใน final ว่าในคอลัมน์ status จะต้องไม่มีค่า NULL นะ แล้วจะต้องมีแค่ค่า 5 ค่านี้ placed, shipped, completed, returned และ return_pending เท่านั้น
เราจะรันแบบนี้ (ไม่มี --data)
dbt test --model final
ผลลัพธ์ที่ได้คือ
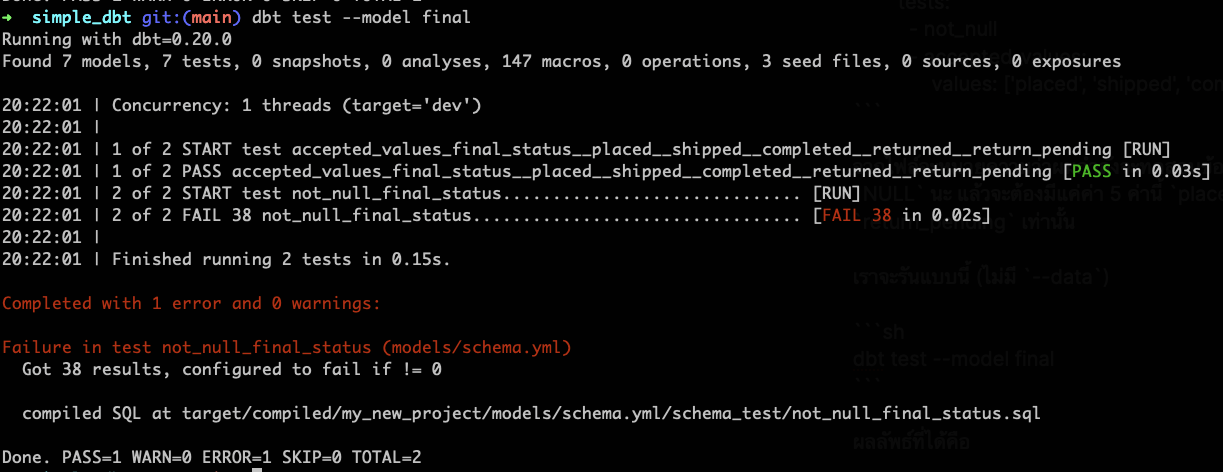
หมายความว่าในข้อมูลผมจะมี status ที่เป็น NULL อยู่นั่นเอง แล้วก็มี Accepted Values ครบตามที่ผมกำหนด ไม่มีนอกเหนือจากนี้
สรุป
OK! เป็นอย่างไรกันบ้างครับกับ dbt 😄 จากบทความนี้น่าจะได้เริ่มเห็นถึงความสามารถของ dbt กันแล้วเนอะ ทั้งการจัดการโมเดล และการทดสอบ ใครได้ลองเอาไปใช้แล้ว หรือตรงไหนที่ดูเจ๋งๆ ก็เอามาแชร์กันได้นะ ☺️
Source Code ทั้งหมดผมเอาไว้ที่นี่ 👇🏻 ลองไปเล่นกันได้ ถ้าเจอบั๊กก็เปิด Pull Request แก้กันมาได้เลยครับ 😂



